Annotated RPN, ROI Pooling and ROI Align
In this blog post we will implement and understand a few core components of two stage object detection. Two stage object detection was made popular by the R-CNN family of models - R-CNN, Fast R-CNN, Faster R-CNN and Mask R-CNN.
All two stage object detectors have a couple of major components:
- Backbone Network: Base CNN model for feature extraction
- Region Proposal Network (RPN): Identifying regions in images which have objects, called proposals
- Region of Interest Pooling and Align: Extracting features from backbone based on RPN proposals
- Detection Network: Prediction of final bounding boxes and classes based on mult-task loss. Mask R-CNN also predicts masks via an additional head using ROI Align output.
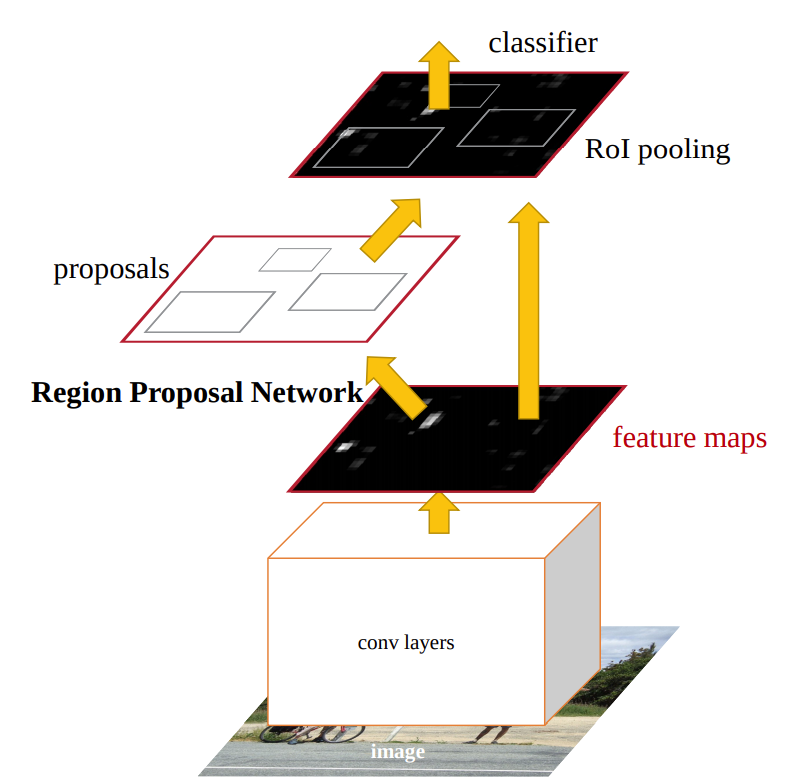
Region of Interest (ROI) Pooling and Alignment connect the two stages of detection by extracting features using RPN proposals and Backbone network. First let’s look at the region proposal network.
Region Proposal Network
The region proposal network takes as input the final convolution layer (or a set of layers in case of UNet kind of architectures). To generate region proposals, a 3x3 convolution is used to generate intermediate output. This intermediate output is then consumed by a classification head and a regression head. The classification head is 1x1 convolution, outputing objectness scores for every anchor per pixel. The regresson head is also a 1x1 convolution that outputs the relative offsets to anchor boxes generated at that pixel.
class RegionProposalNetwork(nn.Module):
def __init__(self, input_size, layer_size, conv_size, num_anchor):
super().__init__()
self.input_size = input_size
self.layer_size = layer_size
self.num_anchor = num_anchor
self.conv_size = conv_size
self.intermediate = nn.Conv2d(
self.input_size, self.layer_size, self.conv_size, stride=1, padding=1
)
self.classification_head = nn.Conv2d(self.layer_size, self.num_anchor, 1)
self.reggresion_head = nn.Conv2d(self.layer_size, 4 * self.num_anchor, 1)
for layer in self.children():
torch.nn.init.normal_(layer.weight, std=0.01)
torch.nn.init.constant_(layer.bias, 0)
def forward(self, feature_map):
t = torch.nn.functional.relu(self.intermediate(feature_map))
classification_op = self.classification_head(t)
regression_op = self.reggresion_head(t)
classification_op = classification_op.permute(0,2,3,1).flatten()
regression_op = regression_op.permute(0,2,3,1).reshape(-1,4)
return classification_op, regression_op
ROI Pooling
Given a feature map and set of proposals, return the pooled feature representation. In Faster RCNN, the Region proposal network is used to predict objectness and regression box differences (w.r.t to anchors). These offsets are combined with the anchors to generate proposals. These proposals are often the size of input image rather than the feature layer. Thus the proposals need to scaled down to the feature map level.
Additionally the proposals can be of different width, height and aspect ratios. These need to be standardized for a downstream CNN layer to extract features.
ROI Pool aims to solve both these problems. ROI pooling extracts a fixed-length feature vector from the feature map.
ROI max pooling works by dividing the hxw RoI window into an HxW grid of approximately size h/H x w/W and then max-pooling the values in each sub-window. Pooling is applied independently to each feature map channel.
import numpy as np
import torch
import torch.nn as nn
floattype = torch.cuda.FloatTensor
class TorchROIPool(object):
def __init__(self, output_size, scaling_factor):
"""ROI max pooling works by dividing the hxw RoI window into an HxW grid of
approximately size h/H x w/W and then max-pooling the values in each
sub-window. Pooling is applied independently to each feature map channel.
"""
self.output_size = output_size
self.scaling_factor = scaling_factor
def _roi_pool(self, features):
"""Given scaled and extracted features, do channel wise pooling
to return features of fixed size self.output_size, self.output_size
Args:
features (np.Array): scaled and extracted features of shape
num_channels, proposal_width, proposal_height
"""
num_channels, h, w = features.shape
w_stride = w/self.output_size
h_stride = h/self.output_size
res = torch.zeros((num_channels, self.output_size, self.output_size))
res_idx = torch.zeros((num_channels, self.output_size, self.output_size))
for i in range(self.output_size):
for j in range(self.output_size):
# important to round the start and end, and then conver to int
w_start = int(np.floor(j*w_stride))
w_end = int(np.ceil((j+1)*w_stride))
h_start = int(np.floor(i*h_stride))
h_end = int(np.ceil((i+1)*h_stride))
# limiting start and end based on feature limits
w_start = min(max(w_start, 0), w)
w_end = min(max(w_end, 0), w)
h_start = min(max(h_start, 0), h)
h_end = min(max(h_end, 0), h)
patch = features[:, h_start: h_end, w_start: w_end]
max_val, max_idx = torch.max(patch.reshape(num_channels, -1), dim=1)
res[:, i, j] = max_val
res_idx[:, i, j] = max_idx
return res, res_idx
def __call__(self, feature_layer, proposals):
"""Given feature layers and a list of proposals, it returns pooled
respresentations of the proposals. Proposals are scaled by scaling factor
before pooling.
Args:
feature_layer (np.Array): Feature layer of size (num_channels, width,
height)
proposals (list of np.Array): Each element of the list represents a bounding
box as (w,y,w,h)
Returns:
np.Array: Shape len(proposals), channels, self.output_size, self.output_size
"""
batch_size, num_channels, _, _ = feature_layer.shape
# first scale proposals based on self.scaling factor
scaled_proposals = torch.zeros_like(proposals)
# the rounding by torch.ceil is important for ROI pool
scaled_proposals[:, 0] = torch.ceil(proposals[:, 0] * self.scaling_factor)
scaled_proposals[:, 1] = torch.ceil(proposals[:, 1] * self.scaling_factor)
scaled_proposals[:, 2] = torch.ceil(proposals[:, 2] * self.scaling_factor)
scaled_proposals[:, 3] = torch.ceil(proposals[:, 3] * self.scaling_factor)
res = torch.zeros((len(proposals), num_channels, self.output_size,
self.output_size))
res_idx = torch.zeros((len(proposals), num_channels, self.output_size,
self.output_size))
for idx in range(len(proposals)):
proposal = scaled_proposals[idx]
# adding 1 to include the end indices from proposal
extracted_feat = feature_layer[0, :, proposal[1].to(dtype=torch.int8):proposal[3].to(dtype=torch.int8)+1, proposal[0].to(dtype=torch.int8):proposal[2].to(dtype=torch.int8)+1]
res[idx], res_idx[idx] = self._roi_pool(extracted_feat)
return res
ROI Align
As your see from the implementation of ROIPool, we do a lot of quantization (i.e ceil, floor) operations to map the generated proposal to exact x,y indexes (as indexes cannot be floating point). These quanitizations introduce mis-alignments b/w the ROI and and extracted features. This may not impact detection/classification which is robust to small pertubations but has a large negative effect on predicting pixel-accurate masks. To address this ROI Align was proposed which removes any quantization operations. Instead bi-linear interpolation is used to compute the exact values for every proposal.
Similar to ROIPool, the proposal is divided into pre-fixed number of smaller regions. Within each smaller regions, 4 points are sampled. The feature value for each sampled point is computed with bi-linear interpolation. Max or average operation is carried out to get final output.
Bi-Linear Interpolation
Bi-linear interpolation is a common operation in computer vision (esp. while resizing images). Bi-linear interpolation works by doing two linear interpolations in x and y dimension in sequence (order of x and y does not matter). That is, we first interpolate in x-axis and then in y-axis. Wikipedia provides a nice review of this concept.
def bilinear_interpolate(img, x, y):
"""Return bilinear interpolation of 4 nearest pts w.r.t to x,y from img
Taken from https://gist.github.com/peteflorence/a1da2c759ca1ac2b74af9a83f69ce20e
Args:
img (torch.Tensor): Tensor of size wxh. Usually one channel of feature layer
x (torch.Tensor): Float dtype, x axis location for sampling
y (torch.Tensor): Float dtype, y axis location for sampling
Returns:
torch.Tensor: interpolated value
"""
x0 = torch.floor(x).type(torch.cuda.LongTensor)
x1 = x0 + 1
y0 = torch.floor(y).type(torch.cuda.LongTensor)
y1 = y0 + 1
x0 = torch.clamp(x0, 0, img.shape[1]-1)
x1 = torch.clamp(x1, 0, img.shape[1]-1)
y0 = torch.clamp(y0, 0, img.shape[0]-1)
y1 = torch.clamp(y1, 0, img.shape[0]-1)
Ia = img[y0, x0]
Ib = img[y1, x0]
Ic = img[y0, x1]
Id = img[y1, x1]
norm_const = 1/((x1.type(floattype) - x0.type(floattype))*(y1.type(floattype) - y0.type(floattype)))
wa = (x1.type(floattype) - x) * (y1.type(floattype) - y) * norm_const
wb = (x1.type(floattype) - x) * (y-y0.type(floattype)) * norm_const
wc = (x-x0.type(floattype)) * (y1.type(floattype) - y) * norm_const
wd = (x-x0.type(floattype)) * (y - y0.type(floattype)) * norm_const
return torch.t(torch.t(Ia)*wa) + torch.t(torch.t(Ib)*wb) + torch.t(torch.t(Ic)*wc) + torch.t(torch.t(Id)*wd)
Now that we understand how bi-linear interpolation works, let’s implement ROIAlign.
class TorchROIAlign(object):
def __init__(self, output_size, scaling_factor):
self.output_size = output_size
self.scaling_factor = scaling_factor
def _roi_align(self, features, scaled_proposal):
"""Given feature layers and scaled proposals return bilinear interpolated
points in feature layer
Args:
features (torch.Tensor): Tensor of shape channels x width x height
scaled_proposal (list of torch.Tensor): Each tensor is a bbox by which we
will extract features from features Tensor
"""
_, num_channels, h, w = features.shape
xp0, yp0, xp1, yp1 = scaled_proposal
p_width = xp1 - xp0
p_height = yp1 - yp0
w_stride = p_width/self.output_size
h_stride = p_height/self.output_size
interp_features = torch.zeros((num_channels, self.output_size, self.output_size))
for i in range(self.output_size):
for j in range(self.output_size):
x_bin_strt = i*w_stride + xp0
y_bin_strt = j*h_stride + yp0
# generate 4 points for interpolation
# notice no rounding
x1 = torch.Tensor([x_bin_strt + 0.25*w_stride])
x2 = torch.Tensor([x_bin_strt + 0.75*w_stride])
y1 = torch.Tensor([y_bin_strt + 0.25*h_stride])
y2 = torch.Tensor([y_bin_strt + 0.75*h_stride])
for c in range(num_channels):
img = features[0, c]
v1 = bilinear_interpolate(img, x1, y1)
v2 = bilinear_interpolate(img, x1, y2)
v3 = bilinear_interpolate(img, x2, y1)
v4 = bilinear_interpolate(img, x2, y2)
interp_features[c, j, i] = (v1+v2+v3+v4)/4
return interp_features
def __call__(self, feature_layer, proposals):
"""Given feature layers and a list of proposals, it returns aligned
representations of the proposals. Proposals are scaled by scaling factor
before pooling.
Args:
feature_layer (torch.Tensor): Feature layer of size (num_channels, width,
height)
proposals (list of torch.Tensor): Each element of the list represents a
bounding box as (w,y,w,h)
Returns:
torch.Tensor: Shape len(proposals), channels, self.output_size,
self.output_size
"""
_, num_channels, _, _ = feature_layer.shape
# first scale proposals down by self.scaling factor
scaled_proposals = torch.zeros_like(proposals)
# notice no ceil or floor functions
scaled_proposals[:, 0] = proposals[:, 0] * self.scaling_factor
scaled_proposals[:, 1] = proposals[:, 1] * self.scaling_factor
scaled_proposals[:, 2] = proposals[:, 2] * self.scaling_factor
scaled_proposals[:, 3] = proposals[:, 3] * self.scaling_factor
res = torch.zeros((len(proposals), num_channels, self.output_size,
self.output_size))
for idx in range(len(scaled_proposals)):
proposal = scaled_proposals[idx]
res[idx] = self._roi_align(feature_layer, proposal)
return res
Testing out implementations
To ensure correctness of our implementations, I wrote some unit tests on simple proposals and also tested out w.r.t reference implementations in pytorch. The code snippet generates random proposals and features, and then compares torchvision outputs with our implementation. I have sucessfully tested out these implementations under various options.
import torch
import numpy as np
from pure_torch_components import TorchROIAlign, TorchROIPool, torch_pred_nms
from torchvision.ops.boxes import nms
from torchvision.ops.roi_pool import RoIPool
from torchvision.ops.roi_align import RoIAlign
device = torch.device('cuda')
torch.set_default_tensor_type(torch.cuda.DoubleTensor)
# create feature layer, proposals and targets
num_proposals = 10
feat_layer = torch.randn(1, 64, 32, 32)
proposals = torch.zeros((num_proposals, 4))
proposals[:, 0] = torch.randint(0, 16, (num_proposals,))
proposals[:, 1] = torch.randint(0, 16, (num_proposals,))
proposals[:, 2] = torch.randint(16, 32, (num_proposals,))
proposals[:, 3] = torch.randint(16, 32, (num_proposals,))
my_roi_pool_obj = TorchROIPool(3, 2**-1)
roi_pool1 = my_roi_pool_obj(feat_layer, proposals)
roi_pool_obj = RoIPool(3, 2**-1)
roi_pool2 = roi_pool_obj(feat_layer, [proposals])
np.testing.assert_array_almost_equal(roi_pool1.reshape(-1,1), roi_pool2.reshape(-1,1))
my_roi_align_obj = TorchROIAlign(7, 2**-1)
roi_align1 = my_roi_align_obj(feat_layer, proposals)
roi_align1 = roi_align1.cpu().numpy()
roi_align_obj = RoIAlign(7, 2**-1, sampling_ratio=2, aligned=False)
roi_align2 = roi_align_obj(feat_layer, [proposals])
roi_align2 = roi_align2.cpu().numpy()
np.testing.assert_array_almost_equal(roi_align1.reshape(-1,1), roi_align2.reshape(-1,1))
Summary
In this post, we implemented a few components of modern object detection models and tested them out. Going through the work of implementing these components helps me better understand the reasoning behind their development. Of course, one would always rely on cuda implementation in actual research work. A logical next step would be to implement the remaining components of two stage object detection and test it out.